About
About this privacy-preserving AI assistant
This assistant runs entirely locally in your browser. The models are loaded locally, provided you have enough resources. All the files and embeddings are also stored locally.
I have built this assistant to experiment with different LLM concepts and adapt them for use in the browser.
This project uses a few key libraries:
- WebLLM for the LLM gives access to many pre-trained models available on Hugging Face.
- Transformers.js for the embeddings. In this case, I'm using a Feature Extraction task to create the embeddings.
The site is hosted on Vercel. It serves the static pages. No data is sent or processed on Vercel, beyond the inevitable IP. The different models are downloaded from Hugging Face, so they, too, will have access to your IP. You can use a VPN or Tor to (somewhat) protect your public IP.
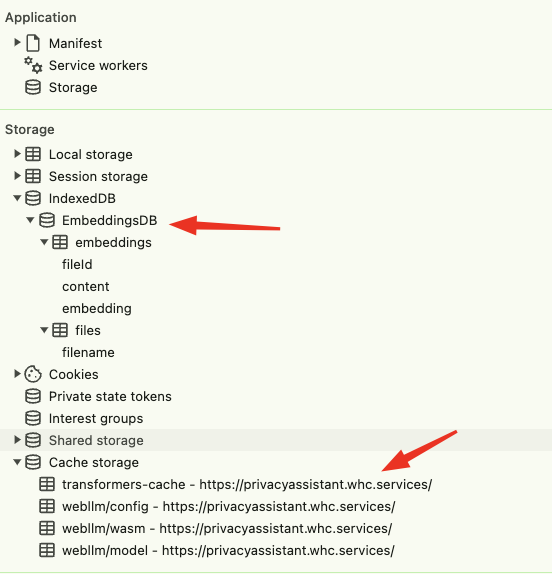
The models and uploaded files are stored in the web application context.
How does this work?
The first step is loading the models. Two models need to be loaded:
- Feature Extraction model to calculate the vector representing a chunk of text.
- Large Language Model (LLM) to consume the question and stored information and generate a response.
These two models are downloaded from Hugging Face.
After this, you have two options:
- Manage files: upload or delete files. Currently this is limited to text and markdown.
- Chat with your assistant
Here is the overall approach:
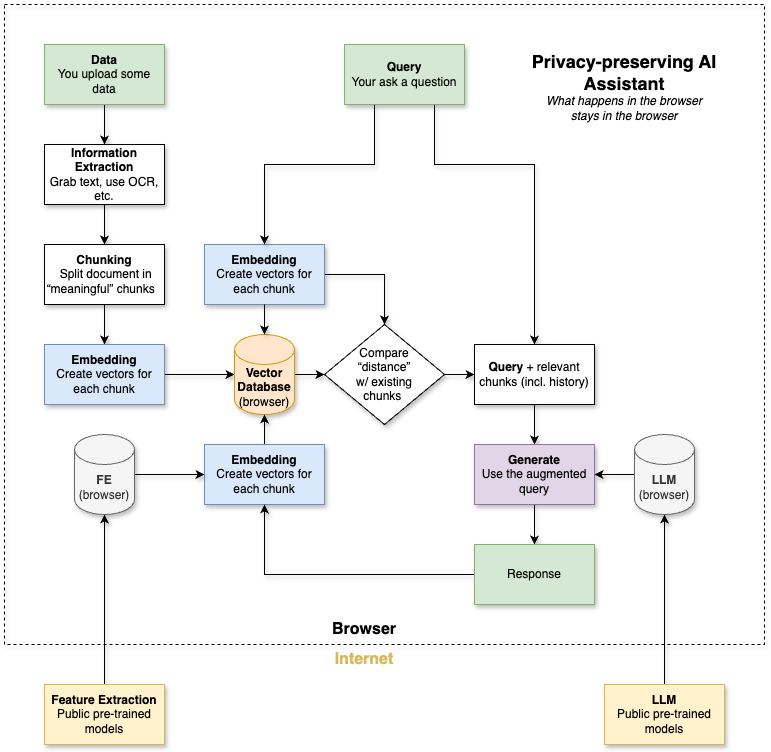
Feature Extraction for Retrieval-Augmented Generation (RAG)
This is used
Large Language Model (LLM)
Future improvements
I might add some more features, if there is some interest:
- Better cleanup of the downloaded models. Currently this can be done manually in the cache storage using the browser's web tools.
- More file types, ideally docx and PDF next.
- Web workers to process embeddings and LLM requests. This would make the browser a bit less laggy when LLM/RAG is being processed.
More details
Models caching
The models and uploaded files are stored in the web application context. You can find the using the browser's developers tools, under the "Application" tab.